AI is shrinking the patch window. Blink helps you harden before attackers exploit it.
Anthropic's Claude Mythos found 2000+ zero-day vulnerabilities in seven weeks. The gap between disclosure and exploitation has collapsed to hours. Patching cycles cannot keep up.
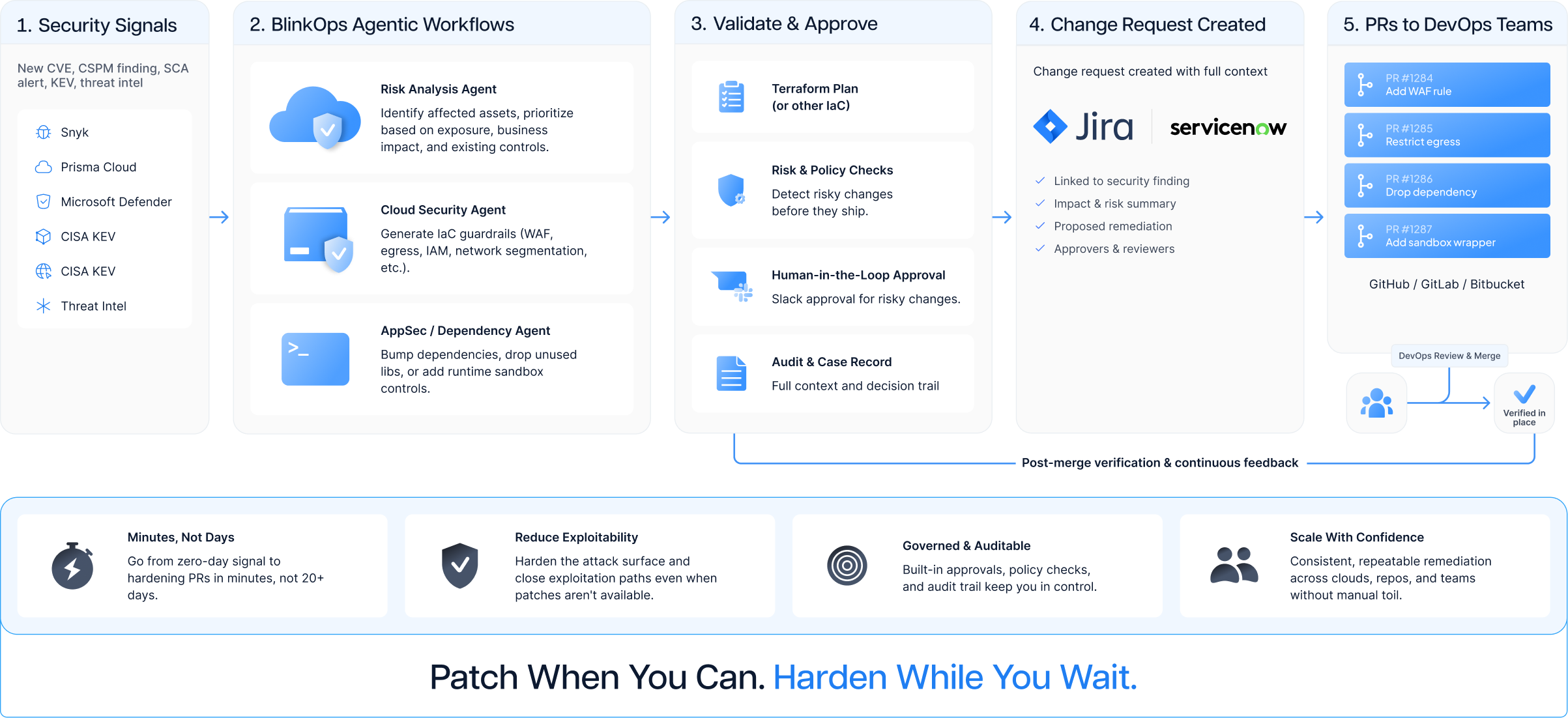
Blink customers don't wait for patches. Agentic hardening generates the right IaC guardrails, the right dependency fixes, and the right approval flow, in minutes, in your team's own DevOps conventions.
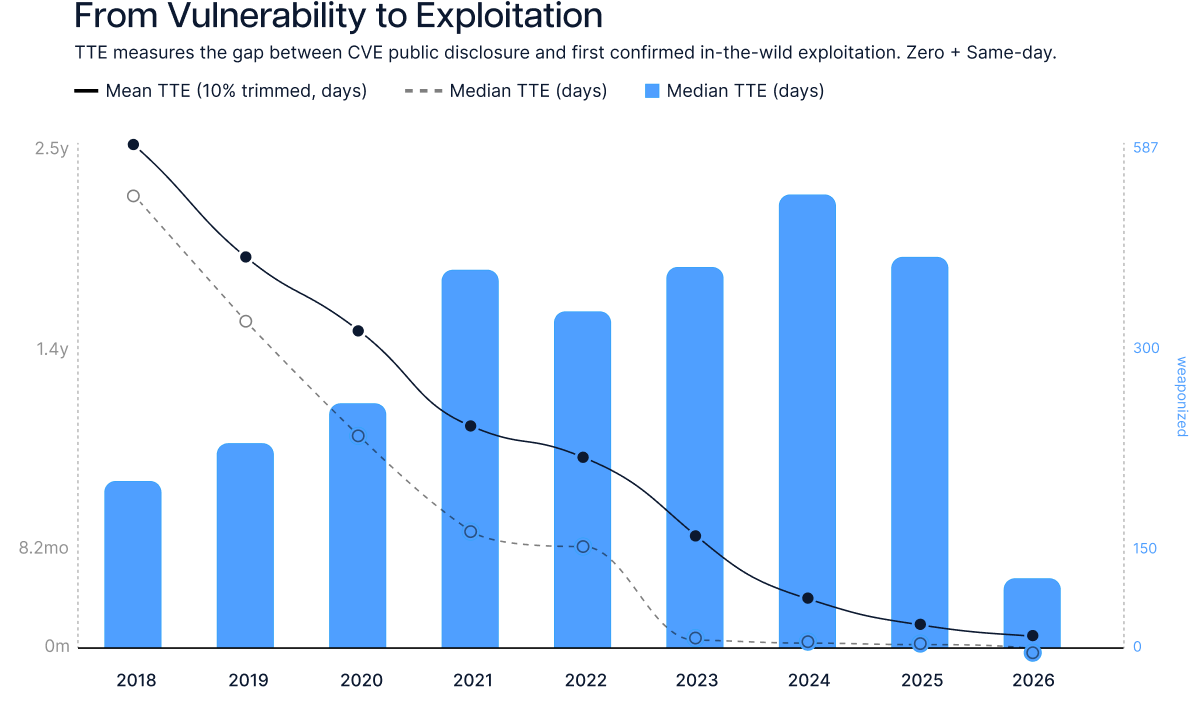
From 771 days to same-day exploitation in seven years.
The Zero Day Clock tracks median time-to-exploit across 3,500+ confirmed-exploited CVEs. The trend isn't slowing. AI now reverse-engineers patches and produces working exploits in minutes. Defenders need 20 days to test and deploy the same patch.
From zero-day signal to governed hardening PRs.
Agentic workflows that prioritize risk, generate safe changes, and route them through the right approvals. From CVE to merged hardening PRs, in your team's DevOps conventions, with human approval where it matters.
Three agents. One outcome.
Each agent has a focused role, a knowledge base specific to your environment, and a tightly scoped set of abilities. They reason. They generate. They route through your approvals.

Prioritizes what actually matters
Identifies affected assets, classifies exposure, and validates whether existing controls already mitigate the risk. Cuts 400 findings down to the 4 that need action today.

Generates IaC guardrails
Writes Terraform, Pulumi, or CloudFormation changes that match your team's repo conventions. WAF rules, egress controls, IAM tightening, network segmentation. Opens the PR with full context.

Fixes dependencies you can't ignore
Agents Maps SBOM to affected services. Bumps versions where a fix exists. Proposes sandboxing, wrappers, or sec-comp profiles where it doesn't. Drops unused dependencies that are pure attack surface.
Agents that know how your company actually works.
Generic "best practice" PRs get closed. Blink agents take your processes, your procedures, and your institutional knowledge as inputs. The output isn't a hardening template pulled from a blog post. It's the specific change that needs to land in your environment, accounting for the exceptions and architectural decisions your team already made.
- 1
Your IaC conventions
Module structure, naming, tagging, branching strategy. PRs match what your DevOps team already ships.
- 2
Your runbooks & SOPs
Module structure, naming, tagging, branching strategy. PRs match what your DevOps team already ships.
- 3
Your exceptions & architectural decisions
Module structure, naming, tagging, branching strategy. PRs match what your DevOps team already ships.
- 4
Your past tickets & decisions
Module structure, naming, tagging, branching strategy. PRs match what your DevOps team already ships.
PR #1284 · Restrict egress on payments-api
CVE-2026-XXXX affects libimage in payments-api.No upstream patch yet. WAF in front. PCI-scoped.
- Using network-module v2.4 per repo standard
- Tagged env=prod, owner=payments
- Branch: sec/cve-2026-xxxx-egress
Webhook callback to provider-x.com
required per Decision Log #218 (2024).
Exception preserved in allowlist.
20 days vs. 15 minutes.
Same CVE. Two response models. The difference is who closes the exploitation window first.
CVE → Patch → Test → Deploy
Wait for the vendor. Wait for the maintenance window. Wait for QA. Hope no one weaponizes the patch faster than you can ship it.
→ ~20 days on average · exposed for 99.9% of vuln lifecycle
CVE → Guardrail PR → Merge
Agent identifies affected assets, generates IaC and dependency PRs in your conventions, validates with terraform plan, routes to DevOps with full context.
→ Minutes to hours · attack path closed before exploitation

The era of "we alert you" is over.
Every security tool on the market promises to find the problem. That bar is no longer enough. The vendors that stand out from here are the ones that can deploy fixes, safe mitigations, or containment actions in real time. Not just tell you that you have a problem. Show that you solved it, or at least bought the team time.
"We alert you."
You have a critical CVE in 412 services. Severity: critical. Patch ASAP.
The alert lands in a Slack channel. Someone triages it. Someone opens a ticket. Someone routes it to the right team. Someone waits for a maintenance window.
Meanwhile, the exploitation window has already closed.
Findings without action
Tickets piling up in backlogs
Patch windows measured in weeks
Defenders always one step behind
"We alert you."
You have a critical CVE in 412 services. Severity: critical. Patch ASAP.
The alert and the response arrive together. Affected assets identified, exposure scored, IaC and dependency PRs already drafted in your team's conventions, validated with terraform plan, routed to the right reviewers.
Even when the patch doesn't exist, the exploitation path is already gone.
Fixes shipped, not just findings reported
Safe mitigations when no patch exists
Containment in minutes, not weeks
Audit trail for every change
Why Mythos is good news for Blink customers.
Most teams read the Mythos announcement and feel the wrong kind of urgency. Defenders get the same tools. The platform that lets you use them first wins.