Patching Can't Keep Up With Mythos. BlinkOps Agents Can.
A few weeks ago, Anthropic announced Claude Mythos. One AI model, one team, in seven weeks, found more than 2000 zero-day vulnerabilities. That's 30% of the world's entire annual output prior to AI. Fox News
•
5
min read
Share this post
A few weeks ago, Anthropic announced Claude Mythos. One AI model, one team, in seven weeks, found more than 2000 zero-day vulnerabilities. That's 30% of the world's entire annual output prior to AI. Fox News
Most of the industry reaction has been some version of "we're cooked." We don't see it that way. For BlinkOps customers, Mythos and the models that will follow it are actually good news. We'll get to why at the end.
First, the problem.
Patching Doesn't Scale
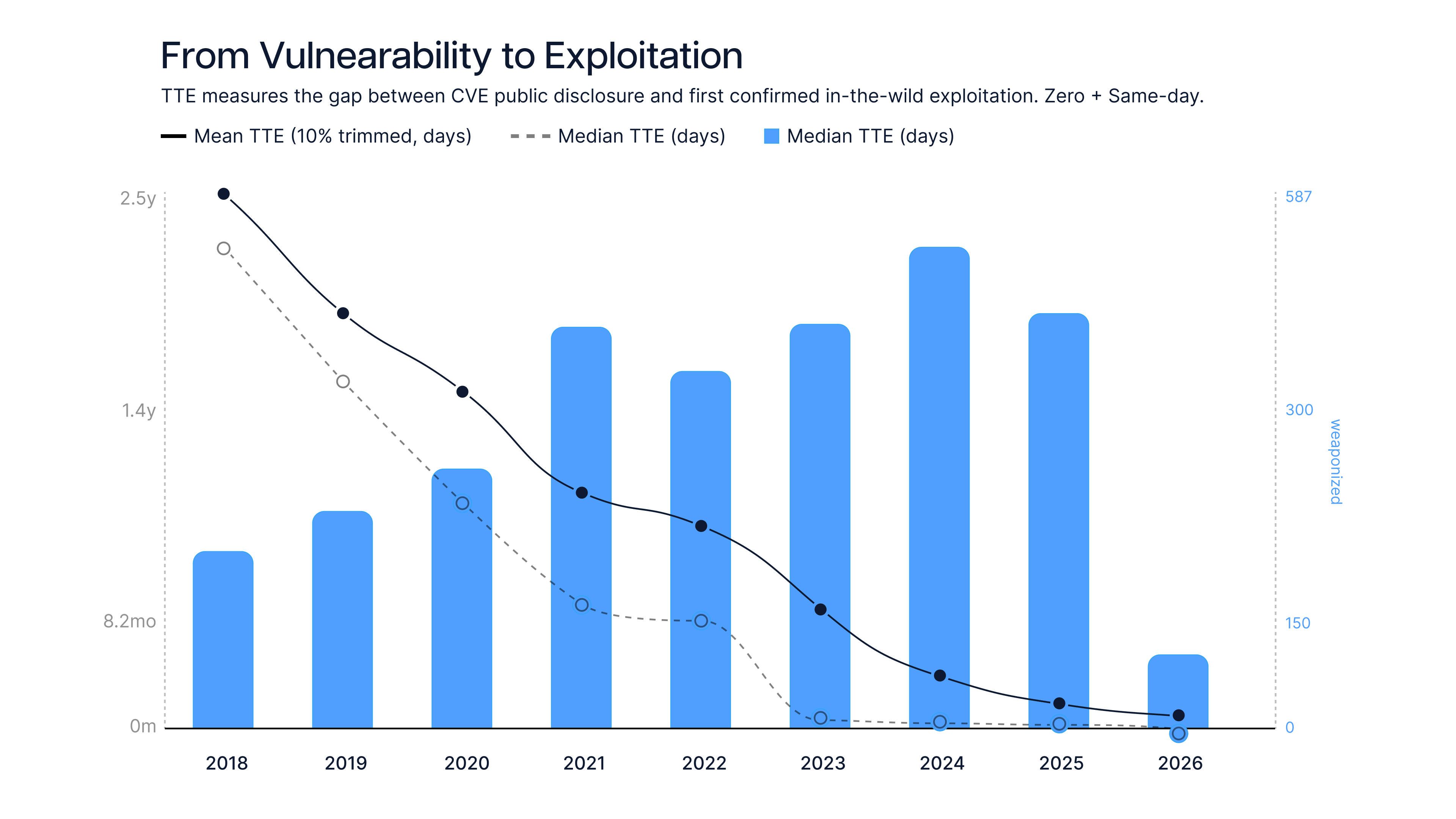
There's a project called the Zero Day Clock that tracks the median time-to-exploit across 83,000+ CVEs. The data tells a story nobody in security ops wants to hear: in 2018, the median time from a vulnerability being disclosed to the first observed exploit was 771 days. By 2023 that window was 6 days. By 2024 it was 4 hours. In 2025, the majority of exploited vulnerabilities were weaponized before they were even publicly disclosed. Zerodayclock
And here's the part that breaks the traditional vulnerability management model: when a software vendor releases a security patch, AI can now reverse-engineer that patch, identify the vulnerability it fixes, and generate a working weaponized exploit in minutes. Organizations need an average of 20 days to test and deploy that same patch.
Halvar Flake had a line about this back in 2004: "the patch is the advisory." Twenty-two years later, AI made that statement existential.
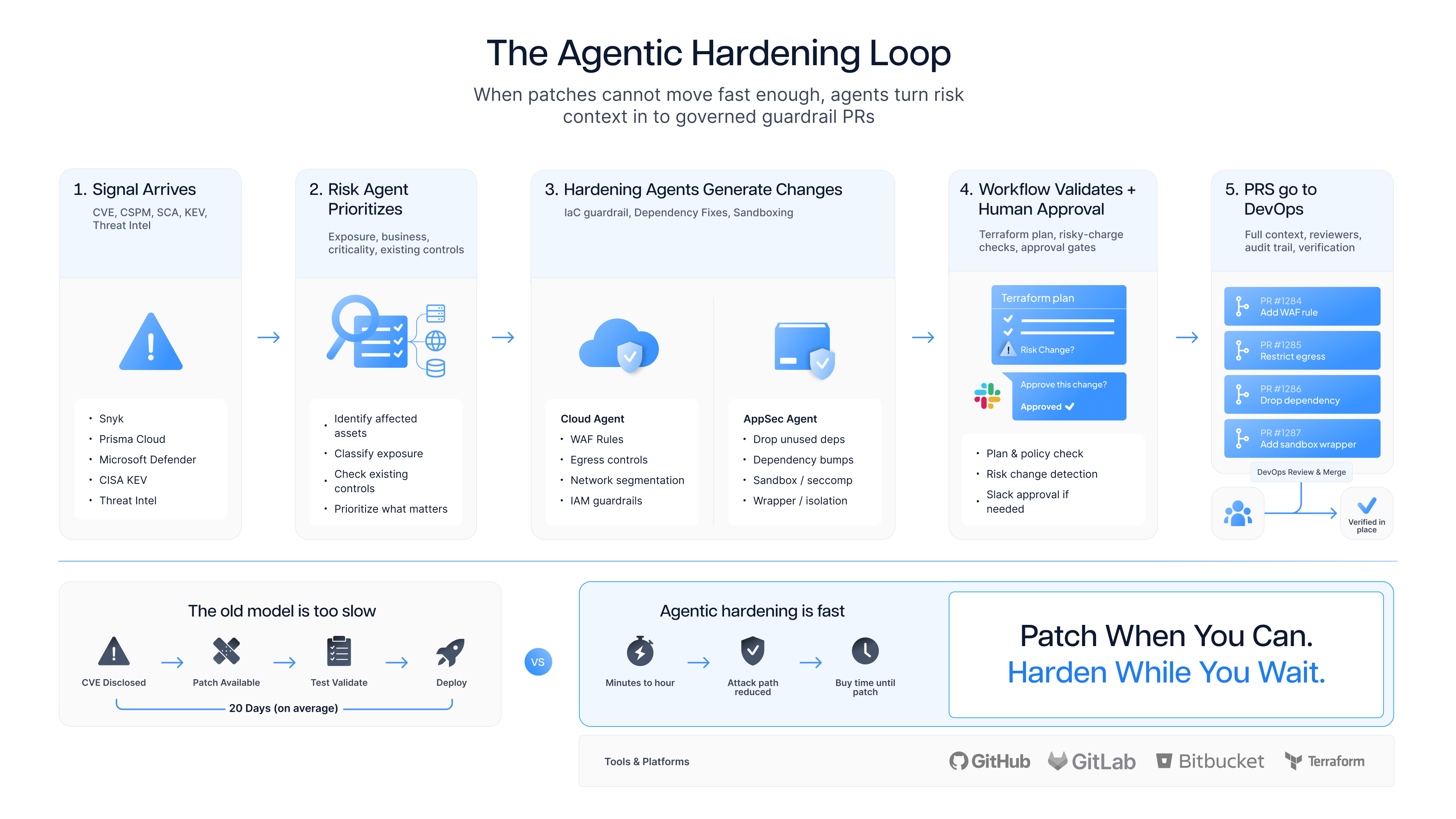
The traditional response to a critical CVE is straightforward. Scanner finds it. Team patches it. Ticket closes. That model assumed defenders had weeks. They don't anymore. And in plenty of cases, patching was never on the table to begin with:
The vendor hasn't shipped a patch yet
The patch exists but breaks a production workload
The system is end-of-life and no fix is coming
The vuln is in a third-party dependency buried four levels deep
The patch requires a maintenance window the business won't approve
You can't out-patch machine speed. So you need a different lever.
Hardening Is the Real Answer
When you can't patch, you harden. Tighten the runtime. Drop the dependency. Segment the network. Sandbox the process. Put a guardrail in the IaC. Reduce the attack surface so even if the bug exists, the exploitation path doesn't.
Phil Venables, former CISO at Google Cloud, calls this "shift down." The real answer is to push security controls into the platforms, frameworks, and infrastructure themselves, so that every developer, every application, and every workload inherits a higher degree of protection automatically. zerodayclock
Sounil Yu makes a similar point with the DIE Triad: build systems that are Distributed, Immutable, and Ephemeral. Vulnerabilities age like milk. Attacker skills age like wine. zerodayclock
The problem isn't that we don't know how to do this. We do. CIS benchmarks, STIG, OPA policies, network segmentation, seccomp profiles, runtime sandboxes. The problem is operational. Nobody has the time to apply hardening at scale across hundreds of services, then write the PRs, get DevOps to merge them, validate they don't break production, and do it all again next week when the next zero-day drops.
This is where agentic automation actually earns its keep.
The AppSec Angle: Your Dependencies Are the Problem
Before we get into the workflow, the AppSec side of this needs its own paragraph.
Any modern application is mostly code you didn't write. A Node app pulls in 800 dependencies. A Python project, same story. A Java app drags transitive libraries everywhere. Your code is maybe 5% of the bytes running in production. The rest is open source you don't control.
Now point a Mythos-class model at every popular library on GitHub. Anthropic announced its AI system Claude had found over 500 high-severity vulnerabilities in widely used open-source software, bugs that had survived decades of expert human review and millions of hours of automated testing. The Anthropic Frontier Red Team warned industry-standard 90-day disclosure windows may not hold up against the speed and volume of LLM-discovered bugs.
What does this look like for AppSec next year?
SCA findings go from 50 critical CVEs in your deps to 500. Then 5000.
Most won't have a fix the day they drop. Maintainers can't patch faster than AI can find.
Even when a fix ships, your dev team can't bump a major version without testing.
The gap between "fix is shipped" and "fix is deployed" is where the entire industry lives.
Patching every dep isn't going to scale. The realistic playbook:
Drop deps you don't actually need
Sandbox the ones you can't drop (egress controls, seccomp, capability drops)
Pin and inventory aggressively, so when a CVE drops you know in minutes which services ship the affected version
Block known-bad versions at the CI
All of that is achievable. None of it gets done at the pace it needs to, because nobody has the bandwidth.
How BlinkOps Customers Are Solving This
The pattern below is one that teams are actively building on the BlinkOps platform. It combines two core building blocks: AI Agent Builder and Workflow Studio.
Quick refresher on how the Agent Builder works. You define an agent by giving it a role, responsibilities, abilities (workflows the agent is allowed to call), and a knowledge base (documents the agent references for context). At runtime, the agent reasons about the task, decides which abilities to call, executes them, and synthesizes a response. Human-in-the-loop approval steps can be embedded in any workflow.
This makes BlinkOps a good fit for the hardening problem, because the work is more reasoning than rote execution. Every CVE has different context. Every DevOps team has different conventions. A static playbook breaks the moment you try to scale it across teams.
Here's how a Cloud Security Hardening pattern comes together.
First agent in the chain. Its knowledge base includes your asset inventory schema, your CMDB data shape, your data classification policy, and any internal risk scoring framework you use.
Configured responsibilities:
Identify affected assets across the environment
Classify exposure (internet-facing vs internal, data sensitivity, business criticality)
Determine if existing compensating controls already mitigate the risk
Produce a prioritized list of assets that genuinely need action
Existing control validation (is there a WAF in front? Is egress already restricted?)
The output is a structured JSON the next agent can consume. The JSON output format is defined in the agent step itself, so downstream steps can rely on the shape.
This step decides whether to continue or stop. A critical zero-day in an air-gapped test system gets scored differently than the same zero-day in a production service handling customer PII. No point opening 400 PRs if 380 of them aren't reachable.
Agent 2: Cloud Security Agent
This is the IaC writer. Its knowledge base is the part that makes the whole thing work, and it's specific to how the customer's team operates:
Your Terraform / Pulumi / CloudFormation repo structure
The agent doesn't just dump a Terraform snippet. It generates a draft PR with a full write-up. What the CVE is. What attack path the guardrail closes. What might break. What to test. The kind of context DevOps engineers actually need before merging a security change.
Agent 3: AppSec / Dependency Agent
Same pattern as Agent 2, but pointed at application code instead of cloud infra. Its knowledge base includes your repo manifest standards (package.json, requirements.txt, go.mod, pom.xml), your SBOM, and your approved-version policy.
For deps with no available fix, the agent can propose a runtime guardrail PR instead (sandbox the call, restrict the syscall, route through a wrapper)
Validation Loop
Before any PR goes out, BlinkOps runs the Terraform plan in the workflow itself. The Terraform integration supports plan and apply commands directly, and there's an existing tutorial that walks through how customers calculate a plan, save it to S3, and gate it on approval before applying.
That same pattern works here. A workflow if step checks the plan output for risky changes (resource deletions, security group widening, IAM expansions). If anything risky is detected, the workflow routes to a Slack approval step using Ask a Question via Slack before the PR even ships.
Human in the Loop
PRs go to the right DevOps reviewers. The case is logged in the BlinkOps Case Management interface so security has full audit trail. If the PR is merged, the workflow can follow up automatically with a verification step that confirms the guardrail is in place post-deploy.
A Quick End-to-End Example
A new memory-corruption CVE drops in a popular image processing library. No patch yet. The CVE allows for outbound exfil through a specific syscall when triggered by a malformed input.
00:00 - CVE webhook fires into BlinkOps from the customer's threat intel feed.
00:01 - Risk Analysis Agent runs. Identifies 412 services using the affected runtime. Of those, 38 are internet-exposed via API Gateway. 14 process PII. 4 of those 14 have no WAF in front.
00:03 - Cloud Security Agent generates two PRs for the 4 priority services. One adds a VPC egress NACL so a popped Lambda can't phone home. The other adds a WAF rule that blocks the malformed input pattern at the edge. Both PRs follow the team's module conventions.
00:05 - Dependency Agent in parallel opens PRs for the remaining 8 services to vendor a sandboxed wrapper around the library calls.
00:06 - Workflow runs terraform plan against each PR. One of the NACL changes is flagged as breaking a legitimate webhook callback. Workflow pauses, asks the on-call engineer in Slack to review.
00:10 - Engineer reviews, confirms the broader fix, the workflow generates a more targeted NACL and reopens the PR.
00:15 - All PRs are out with full context. DevOps reviews and merges through normal channels.
Same day - The 4 highest-risk services are no longer reachable for that exploit path. No patch was needed. The bug is still there. The exploitation path is gone.
That's the difference between a 20-day patch window and a 15-minute hardening window.
What Customers Need to Get Right
This isn't plug-and-play, and the BlinkOps team is direct about that with customers:
Agents are only as good as the knowledge they're given. If your IaC is inconsistent and your SBOM is six months stale, the agent's output will reflect that. Fix the inputs first.
Hardening can break things. Even with risk analysis, you need staging, canary deploys, and rollback plans. Auto-merge to prod is not the goal.
Not every guardrail is expressible in code. Some hardening lives in network appliances, EDR rules, or runtime configs the IaC doesn't reach. BlinkOps can orchestrate those too, but the workflow design is different.
This doesn't replace patching. Hardening buys time. When a fix exists and is safe to apply, apply it.
Build review loops where engineers learn from what the agents produce. Skills atrophy if the agents do all the work and humans only rubber-stamp.
Why Mythos Is Good News for BlinkOps Customers
Back to the framing we started with. Most people read the Mythos announcement and feel the wrong kind of urgency. They see "AI finds zero-days at machine speed" and think the attackers won.
Here's the actual read: defenders get the same tools.
Mythos isn't broadly available yet. Anthropic released it to a small set of trusted partners under controlled conditions, with a six-to-twelve month window before adversaries replicate the capability. At some point, models with similar reasoning capabilities will be accessible to defenders directly. When AISLE tested Mythos's showcase vulnerabilities on small, cheap, open-weights models, eight out of eight models detected the flagship FreeBSD exploit, including one with only 3.6 billion active parameters costing $0.11 per million tokens. The capability is already leaking down. The Next WebAISLE
When stronger models land, the customers who get the most value are the ones who don't have to rip out their automation platform to take advantage of it.
This is where BlinkOps' model-agnostic design matters. The Agent Builder doesn't hard-code a single LLM. Customers choose the provider per agent step. The platform supports Anthropic, OpenAI, Google Gemini, and others as connected providers, and the Generate Model Response action exposes the model as a parameter you can switch at any time.
What that means in practice:
Today, your Cloud Security Agent might run on Claude Sonnet or GPT-4. Fine for most hardening work.
When a Mythos-class model becomes available for production use, you change the model field in the agent step. No re-architecture. No platform migration. The same workflows, the same knowledge bases, the same approval steps. Better reasoning underneath.
For sensitive work, route specific agent calls to a self-hosted model. For high-volume routine work, use a cheaper one. The choice is yours.
Every time a stronger model ships, BlinkOps customers get stronger. The platform doesn't bet on a single provider, so the reasoning improvements compound automatically. Better triage. Better PR drafts. Better risk analysis. Same workflows.
That's the asymmetry. Attackers using Mythos-class tools is a serious problem. Defenders using Mythos-class tools, plugged into the workflows that already exist, with the knowledge bases already populated, with the approvals and integrations already wired up, is a serious answer.
Closing Thoughts
Look at the Zero Day Clock one more time. 771 days. Then 6. Then 4 hours. Then zero. zerodayclock
That curve isn't bending back. The "find it, fix it, patch it" model was built for a world where exploitation took months. That world is gone.
The next phase of vulnerability management isn't about patching faster. It's about hardening at the pace of the threat. Guardrails in the IaC. Dependencies dropped or sandboxed. Egress controlled by default. Ephemeral, immutable, segmented infrastructure as the baseline.
The reason this hasn't happened at scale yet is operational, not technical. Writing the right hardening for each environment, in the conventions each team uses, with the context DevOps needs to actually merge the PR, is exactly the kind of work that doesn't scale with humans alone.
That's what BlinkOps was built for. Purpose-built agents that know your environment, write the change, explain the why, and route it through the right approvals. Workflows that handle the orchestration and validation. Humans where the judgment matters. And a model-agnostic foundation that lets you adopt the next generation of reasoning models the moment they're ready, without rebuilding anything.
Patching will keep happening. Apply patches when you can. Until then, harden everything that moves.
When Mythos lands for defenders, BlinkOps customers will already be using it.
.webp)
.webp)






.png)

