Using BlinkOps Case Management to Actually Move the Needle in Vulnerability Management
Anyone who’s run a Vulnerability Management (VM) program knows the drill: scanners light up with thousands of findings, the queue keeps growing, and teams get stuck debating what to fix first. By the time tickets make it to engineering, half of them are stale.
Olivia Lomax
October 10, 2025
•
6
min read
Share this post
Anyone who’s run a Vulnerability Management (VM) program knows the drill: scanners light up with thousands of findings, the queue keeps growing, and teams get stuck debating what to fix first. By the time tickets make it to engineering, half of them are stale.
That’s why I started leaning on BlinkOps Case Management for vulnerability management workflows. Instead of drowning in alerts, I use cases as the backbone for prioritization and orchestration. Here’s how it works in practice:
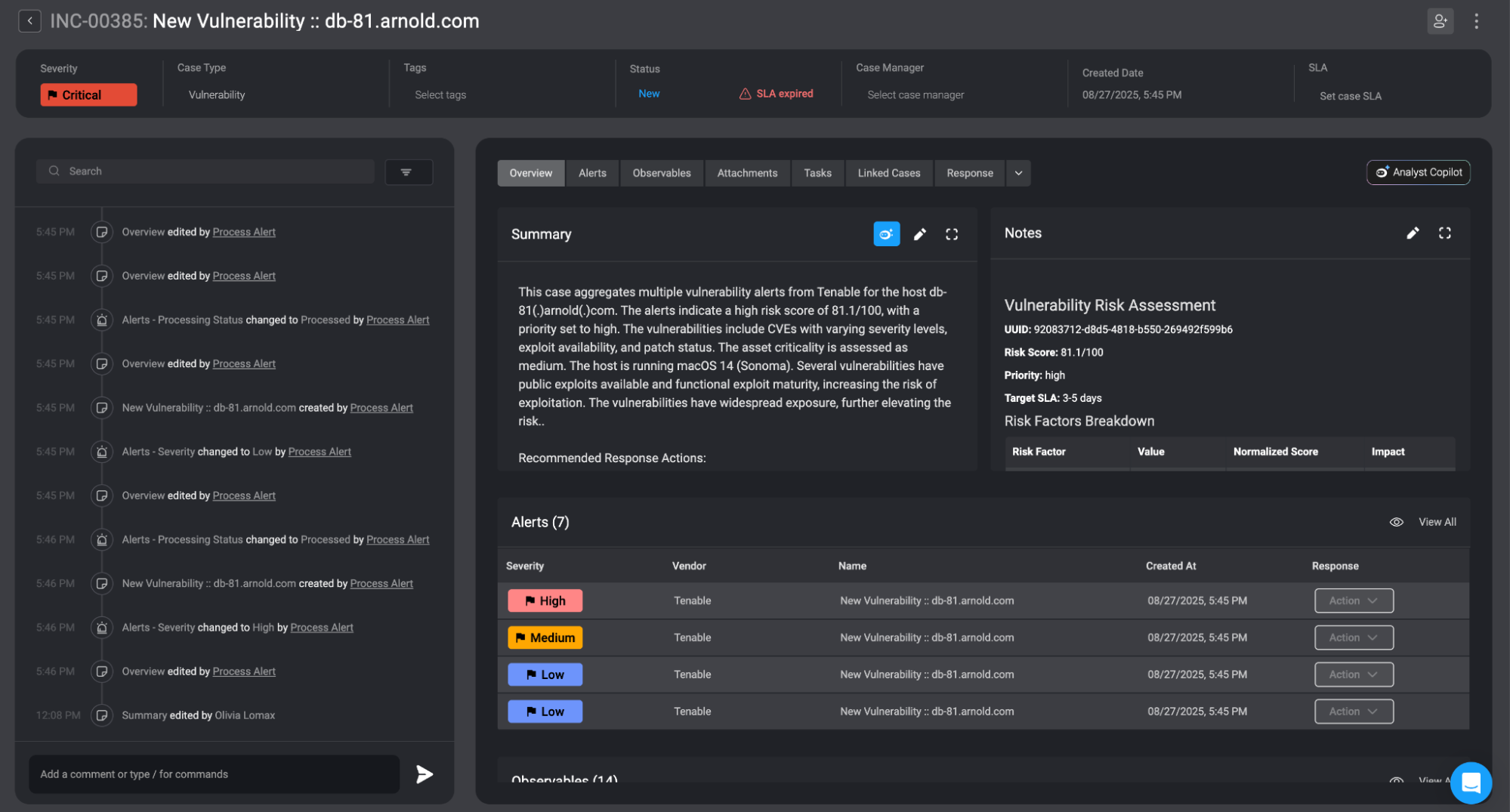
Cases Built Around Assets
Rather than juggling thousands of individual CVEs, I spin up a single case for each host. That case becomes the place where I aggregate:
All vulnerability alerts for that asset
Enrichment data from multiple sources
Prioritization logic (more on that below)
Response actions I can take right there in Blink
Now instead of “alert soup”, I get a clear, contextual view of what’s actually happening on a system. Additionally, remediation teams get one object they can own.
Enrichment Drives Prioritization
I built a custom script that pulls in external intel (EPSS, KEV, exploitability data, asset criticality). Each vuln in the case gets scored, then bucketed as Critical, High, Medium, or Low.
What that means in practice:
Engineers don’t waste cycles patching noise.
I know which hosts actually pose risk to the business.
The team can report progress in a way that makes sense to leadership.
It’s a huge difference between “we patched 400 CVEs” and “we reduced exploit risk on our crown jewel assets by 80% in a week.”
Built-In Response Actions
Cases aren’t just static containers. With BlinkOps, I can fire off actions at different levels:
On observables: Run lookups, check indicators, and submit blocks.
On vulnerabilities: Kick off patch tickets, validate exploitability, and apply compensating controls.
On the case itself: Close it out, escalate, or generate a remediation report.
All of this without leaving the platform. That’s the real value, context + automation in one place.
Exception Tracking & False Positives Made Simple
Every VM team runs into the same two headaches:
False positives that waste analyst time.
Exceptions where the business decides not to patch something right away.
With Blink’s flexible case management and easy-to-build workflows, both are much easier to handle. Analysts can tag or suppress a false positive directly in the case, and that logic can be automated for future scans. Exceptions can be tracked with workflows that set expiration dates, send reminders, or automatically re-open the case when it’s time to revisit.
Instead of losing visibility (or tracking it all in a spreadsheet), exceptions and false positives stay right alongside the rest of the vulnerability data where it is documented, automated, and auditable.
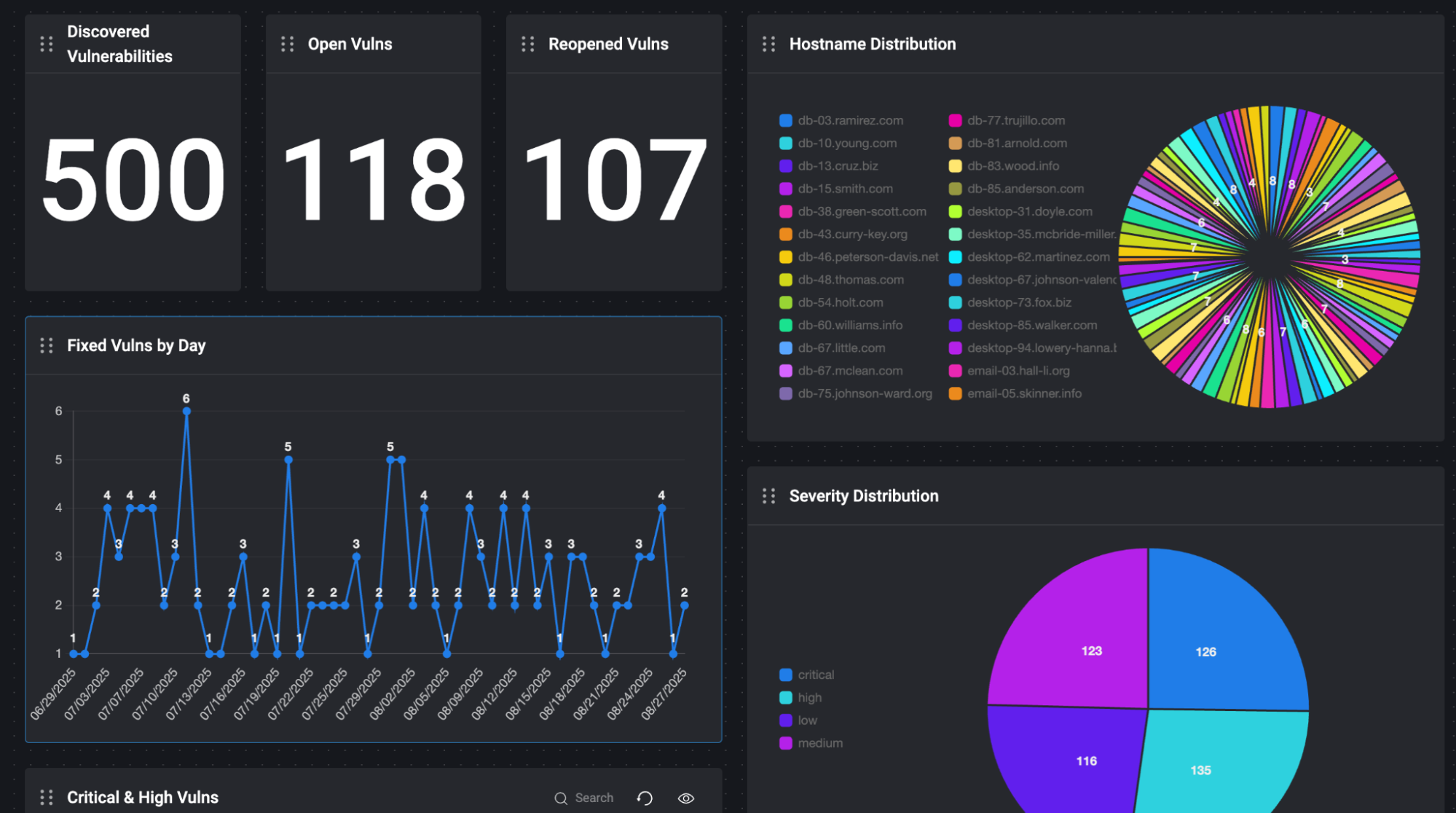
Dashboarding & Reporting Without the Pain
Half the battle in VM is reporting and dashboarding. Security leaders want to see risk trending down, engineers want to know what’s on their plate, and executives want crisp metrics they can drop in a board deck.
Because BlinkOps cases already centralize enrichment, severity, and remediation status, dashboarding becomes automatic. You can slice cases by criticality, track remediation efficiency over time, spotlight the riskiest assets, and even break out how many findings were closed as false positives or exceptions. No pivot tables, no manual exports, just reporting straight from the case data.
Why This Matters
Traditional VM breaks down between finding and fixing. BlinkOps case management bridges that gap. It:
Cuts down noise by rolling alerts into focused cases
Adds context through enrichment and scoring
Makes action simple with built-in playbooks
Streamlines exception tracking and false positive handling
Provides dashboards and reporting execs actually care about
Tracks remediation end-to-end
The result? A process that actually scales, engineers that trust prioritization, and execs who see measurable risk reduction instead of patch counts.
Wrapping Up
For me, case management is what turns VM from a reactive grind into a proactive, risk-driven workflow. Cases give structure, enrichment gives brains, automation gives hands. Put it all in BlinkOps, and you finally get a program that keeps up with the volume and still shows clear business value.
.webp)
.webp)